
|
Filosofibiblioteket Om meg Bokmerker i dette dokumentet |
Evaluering av informasjonspålitelighet. (IP-teorien)
Denne refleksjonen ble skrevet som en del av mine bokprosjekter på slutten av 80-tallet. I deler av fremstillingen er jeg nok veldig «ingeniør». Men meningen med det hele har lite med praktisk bruk å gjøre. Fremstillingen er teoretisk, og formlene for sannsynlighet er kun ment som en detaljert (med teskei) fremstilling av hvorfor all empirisk informasjon er usikker. Dette er drevet av utallige debatter jeg var involvert i hvor mennesker fremstår som skråsikre og påståelige. Jeg ble etter hvert fasinert av en ide om å bedømme alle mine forestillinger som sannsynlige. Hvor sannsynlige de er, avhenger av en del omstendigheter. Disse omstendighetene har jeg forsøkt å analysere i denne fremstillingen. Jeg vokste opp i en atmosfære preget av kristen konservativ tenkning. Men av og til kom lærde pastorer på besøk. En gang, jeg husker ikke omstendighetene, så fikk jeg høre noen sitere Descartes: «Jeg tenker derfor er jeg». Dette utsagnet gjorde et uutslettelig inntrykk på meg. Vanligvis var jeg omgitt av vage bibelsitater, og enda vagere fortolkninger, en stor sort graut som ble håpløs for en ungdom å konsumere og finne noe å holde tak i. Descartes berømte utsagn representerte for meg det naturlige bunnsolide utgangspunkt for alt. For dette skapte en bevissthet om mitt eget jeg og en bevissthet om å forholde seg til alt som kommer til meg som noe som trenger kritisk evaluering. Ting er ikke nødvendigvis slik som de fremstår for mitt sinn. Den viktigste kilde til informasjon er mine medmennesker og alt som kommer rekende forbi, skriftlig og muntlig. Alt dette utgjør, til sammen, et inkonsistent materiale av tilfeldige punktnedslag av hva som måtte finnes der ute. Det er et tilfeldig millimeterutdrag av den samlede store kollektive menneske samtale. Kanskje har jeg en gang i barndommen hatt en naiv oppfatning om en verden som forholdsvis lett lar seg begripe, om man bare er villig til det. Det er en forestilling som nok så raskt ble svekket. Men jeg har nok fått en følelse av at mine omgivelser absolutt ikke opplevde det på samme måte. Og selvsagt ble ethvert forsøk på å forklare mine tanker nokså raskt klippet av retorikere og andre som ville bruke arenaen til helt andre formål.
Da jeg senere utviklet mine egne erkjennelsesteoretiske refleksjoner så bygger jeg videre på tankene i dette dokumentet. Det samme gjelder beslutningsteorien, hvor konsekvensene inngår som sannsynligheter i beslutningsregnskapet. Dette passer som hånd i hanske med teorien om informasjonspålitelighet. I så måte er dette en grunnleggende byggestein i min måte å tenke på.
Jeg klarer ikke å forestille meg annet enn at de fleste som leser dette vil se på det som naive selvfølgeligheter som ikke trengs å beskrives på en slik detaljert måte. Utmerket sier jeg. For kanskje er mine opplevelser i ungdommens debatter kun en opplevelse av retorikk.
Lenge etter at dette ble skrevet gjorde filmen Matrix storsuksess verden over. Filmen virket forløsende på denne delen av min frustrasjon. For den som virkelig forstår dybderefleksjonen i denne filmen, den har forstått hva jeg forsøker å si.
«Det vi vet er vitenskap, det vi tror vi vet er uvitenhet» sa Hippokrates. Hvor mye vet vi egentlig? Hvor kommer vår viten fra? Dette er gamle filosofiske stridsspørsmål, men like aktuelt i dag. Kilden for vår kunnskap kan komme innenfra, fra oss selv eller den kan komme utenfra. Filosofene på 16 -1700-tallet var tidels sterkt opptatt av dette. På den ene siden har vi filosofer som Descartes, Spinoza og Leibniz som mer eller mindre hevdet at vår viten stammet fra medfødte ideer. Ved hjelp av fornuften skulle vi kunne slutte oss til hvordan virkeligheten er. På den andre siden har vi de britiske empirister representert ved Locke, Berkeley og Hume som hevdet at all kunnskap kom utenfra, via våre sanser, eller som Berkeley hevdet, fra Gud. Alle de nevnte filosofer utviklet sine egne selvstendige teorier om dette, men det grunnleggende spørsmål er aldri blitt løst: Kommer vår viten innenfra, eller utenfra, og hvor sikker kan vi være? David Hume er vel den filosofen som har gått lengst i å erkjenne usikkerhet. Ifølge Hume kunne vi stort sett ikke være sikker på noen ting. Alt er bare sannsynligheter. Et slikt resonnement må nødvendigvis skape store problemer. Vi kommer avgjort i stor mangel på absolutte sannheter, vi kommer aldri lengre enn til Descartes "Jeg tenker, derfor er jeg". Immanuel Kant gjorde et godt forsøk på å løse dette problemet. Han hadde inngående kjennskap til striden mellom rasjonalistene og empiristene. Mest havnet nok Kant på empiristenes side, men ved hjelp av en del geniale resonnementer trakk han den konklusjonen at vi kunne erkjenne flere absolutte sannheter. Dette gjaldt f.eks. oppfattelse av tid og rom, og at enhver begivenhet må ha en årsak (kausalitetsprinsippet). I erkjennelsesteorien skal vi trenge videre inn i disse spørsmålene. For å kunne gjøre dette på min måte trenger jeg et tankeredskap for å påvise usikkerhet, det er IP-teorien.
Vi har før vært inne på at grensene mellom informasjon og kunnskap er diffuse. Egentlig er det subjektivt. Om denne viten skal ses på som kunnskap, informasjon eller data er egentlig avhengig av behovet. Jeg definerer informasjon slik:
Informasjon er forflytning av kunnskap
Forflytningen av kunnskap skjer i informasjons-prosessen (IP). I informasjonsprosessen inngår det tre fysiske enheter:
1. avsender
2. media
3. mottaker
Media er altså det fysiske bindeleddet mellom sender og
mottaker. Det kan være papir, røyk-signaler, elektromagnetiske bølger, vibrerende
luft (lyd), disketter, telefonlinjer osv. Dette er alle naturlige media. Vi
skal senere komme inn på kunstige media, som først og fremst er mennesker og
dyr. Media overfører signaler, disse signalene kalles data, eller signalstrøm.
Dataene bærer informasjonen. Data kan derfor også kalles for
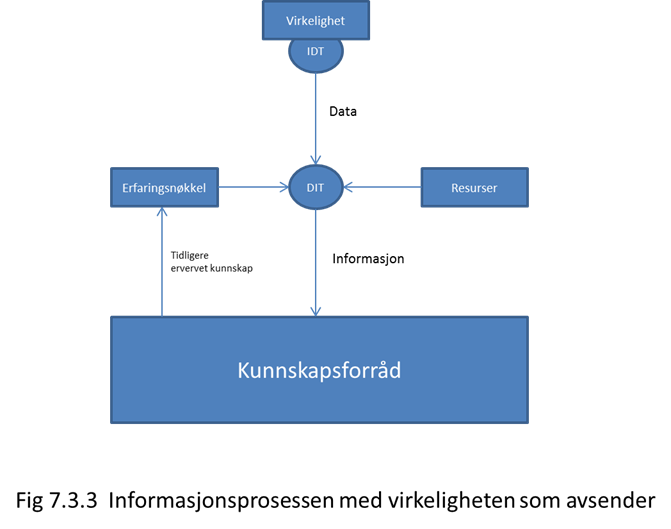
informasjons-bærer. Under informasjonsprosessen foregår det en prosess på  Fig 7.3.1
Fig 7.3.1
Sendersiden, og en på mottakersiden. Prosessen på sendersiden kaller jeg for IDT-prosessen (Informasjon-Data-Transformasjons- prosessen). Denne prosessen består i at informasjon blir transformert til data som er egnet til å sende over media, og at det sendes over media.
Prosessen på mottakersiden kaller jeg for DIT-prosessen (Data-Informasjons-Transformasjon). Her foregår det motsatte av IDT-prosessen; data mottas fra media og transformeres til informasjon. Modellen er illustrert i fig. 7.3.1. Vi skal nå se litt nærmere på disse to prosessene.
For å transformere mellom informasjon og datasignal trenges det resurser, og det trenges en kode-nøkkel. Resursene kan være energi, tid, intelligens osv. Data er kodet informasjon. For å få ut informasjonen må dataene dekodes. Til dette trenges en nøkkel, eller en protokoll som beskriver hvordan dataene skal ordnes for at informasjonen skal kunne trekkes ut. IDT og DIT er illustrert i fig 7.3.2

Akkurat som overgangen mellom informasjon og kunnskap er subjektiv, er også overgangen mellom data og informasjon subjektiv. Dette kommer av at informasjonsprosessen kan foregå på flere nivåer. La oss se på et eksempel:
La oss tenke oss følgende informasjonsoverføring. I en skoleklasse skriver en gutt "Jeg elsker deg, hilsen Knut" på en lapp, bretter den sammen, skriver Mona på utsiden, leverer den til sidekammeraten som sender den videre til en som igjen sender den videre osv. inntil den når Mona. Mona åpner lappen og leser den.
IDT-prosessen foregår hos Knut. Han starter med en informasjon som han ønsker å overbringe til Mona. Informasjonen blir omsatt til språk. Til dette bruker Knut sin kunnskap om norsk språk. Deretter blir språket festet på papir. Til dette bruker Knut sin kunnskap om norsk skriftspråk og om norske skrifttegn. I denne prosessen har Knut transformert den psykiske informasjon til en fysisk realitet. Nøkkelen er det norske skriftspråk. De resursene han har brukt er: tid, fysisk og psykisk energi, penn og papir, kunnskap om norsk skriftspråk. Dataene er nå preget på papir. Media er mennesker papir og blekk.
Når Mona får lappen på pulten, må den motsatte prosessen skje: Hun må transformere dataene til informasjon. Det første hun må gjøre er å plukke dataene fra media. Det består i at hun åpner lappen og ser på blekkets form på papiret. Dette er grunndata. Den første nøkkel hun bruker er sin viten om hvordan bokstaver ser ut, deretter sin viten om hvordan bokstavene settes sammen til ord. I denne prosessen er dataene transformert fra fysiske til psykiske data. Dersom Mona ikke forstår norsk kommer hun ikke lengre. Hun kan lese ordene, delvis uttale dem, men hun kjenner ikke ordenes innhold. Dersom Mona er norsk har hun lest denne setningen så mange ganger at hun kanskje ikke behøver å stave seg gjennom ordene. Hun vet hvordan setningen "Jeg elsker deg" ser ut. Mona sitter nå med den informasjon at Knut har skrevet "Jeg elsker deg til henne". For henne er det blitt til kunnskap. Men hva skal hun legge i dette? Setningen må tolkes videre. Har dette noe med Knuts følelser å gjøre, eller kanskje det har noe med hans humor å gjøre. Vi kan nå se på hennes viten som data som må bearbeides videre. De må tolkes. For å kunne gjøre dette må hun ha en ny nøkkel. Denne nøkkelen har ikke lengre noe med norsk språk å gjøre, den har noe med kjennskap til avsenderen. Ut fra dette kan Mona sitte inne med den kunnskap at Knut har sterke følelser for henne.
Men la oss nå si at en forsker prøver å lære litt om kjærlighetslivet til 9-klassisinger. I denne forbindelse svarer 1000 elever på et spørreskjema. Blant spørsmålene kan det f.eks. være et som lyder slik: "Vet du om noen i din klasse er forelsket i deg?" På dette svarer Mona ja. Dette ja, er data for forskeren. De må tolkes i en større sammenheng, for å kunne gi den informasjon forskeren er ute etter. Dersom han får ut denne informasjonen får han ny kunnskap.
Det finnes to typer nøkler:
1. Protokoll-nøkkel
2. Erfarings-nøkkel
Protokoll-nøkkelen er avtalt. Det vil si at IDT og DIT bruker en avtalt standard for hvordan informasjonen skal representeres. Innenfor datakommunikasjon kalles dette for en protokoll. Slike protokoller er en nødvendighet for all kommunikasjon. Det norske språk er en slik protokoll, som brukes av nordmenn. Men informasjonsprosessen kan benytte seg av andre nøkler enn de som gjelder for vanlig kommunikasjon. Det er erfarings-nøkkelen. Erfaringsnøkkelen kan brukes i de tilfeller der ingen protokoll er avtalt. Den anvendes typisk kun i DIT prosessen. Ressurser for å kunne anvende en slik nøkkel er kunstig eller naturlig intelligens. Nøkkelen består av erfaring, altså kunnskap som finnes fra før. I de fleste tilfeller er IDT prosessen på dette nivå ubevisst, eller den er naturlig. Det kan f.eks. være et naturfenomen. I et naturfenomen foregår det ingen bevisst koding av de data vi ønsker. Dersom vi ønsker informasjon ut av de data vi mottar må disse tolkes ut fra tidligere kjennskap hvordan fenomenet sender ut disse data. For rene naturfenomener er det selve de fysiske hendelser som er nøkkelen.
Vi vet av erfaring hvordan flater sender ut lys. Ut fra denne viten kan vi si noe om formen på et legeme ved å se på det. Nøkkelen er tidligere erfaring. I eksemplet overfor brukte Mona tidligere erfaring for å avgjøre om Knut elsket henne, eller om han f.eks. hadde en spesiell form for humor.
I figur 7.3.4 ser vi hvordan informasjon kan trekkes ut av et naturfenomen for å bygge opp kunnskap. Her er IDT-prosessen en naturlig fysisk prosess som er en del av, eller hele naturfenomenet. Erfaringsnøkkelen er et utvalg fra et tilgjengelig kunnskapsforråd. Den består konkret av forestillinger om hvordan fenomenet manifesterer seg for sanseapparatet.
Media består av en kjede med fysiske enheter som kan flytte data. Disse enhetene kan splittes opp i enkeltledd. Dette kalles for dataoverføringsledd. I eksemplet overfor var Knuts kammerat et slikt ledd, fordi han flyttet data, fra ett ledd til det neste. Dataoverføringsledd kan ofte internt deles opp i flere ledd.
Et eksempel på dette kan f.eks. være overføringen av et TV bilde. Leddene kan da f.eks. være kamera, mikser, forsterker, sender, omformer, antenne, TV mottaker, øye, hjerne osv. Dette er en sterk forenkling av situasjonen. Det er ikke vanskelig å finne flere ledd i en slik kjede. TV mottakeren kan f.eks. deles opp i kanalvelger, MF forsterker, luminans og fargekretser, videoforsterker og billedrør. Videre kan kanalvelgeren deles opp i HF kretser, oscillator og blandetrinn. Blandetrinnet kan deles opp i transistorer spoler og kondensatorer. Disse kan igjen deles videre opp. Det kan være uendelig mange punkter i en slik kjede.
Forvrenging av informasjon er:
Omforming av informasjonen på en slik måte at det oppstår avvik i korrespondens mellom avsendt kunnskap og oppfattet kunnskap.
Legg merke til at jeg har brukt uttrykket "oppfattet kunnskap" i stedet for "mottatt kunnskap". Grunnen til dette er at der også kan skje forvrenging i mottaker.
Informasjon er kunnskap i bevegelse. Og dette er basis for den videre drøfting, nemlig at det å flytte kunnskap er informasjons overføring. En slik forflytning medfører nødvendigvis friksjon. For å trekke parallellen til fysikkens verden: Vi vet at legemer i bevegelse alltid utsettes for motstand fra omgivelsene. Et unntak er bevegelse i vakuum uten kraftfelt. Et legeme i bevegelse representerer en bestemt mengde bevegelses energi. Krefter og friksjon fører til tap av bevegelsesenergi. Energien overføres til andre energiformer. På samme måte vil kunnskap i bevegelse, som er informasjon, møte mekanismer som svekker denne, og overfører den til andre energiformer. Denne friksjonen er med på å forvrenge informasjonen.
Informasjonsprosessen kan informasjonen forvrenges på fire måter:
1. Dataforvrenging
2. Resursforvrenging
3. Nøkkelforvrengning
4. Kausalitets-forvrengning
Dataoverføring er avhengig av fysiske media. Det er fysisk forvrenging av signalet. Årsakene til forvrengningen kan for eksempel være støy, avstand, tid, feil osv. Innenfor all fysisk kommunikasjon er dette et kjent fenomen. Et radiosignal svekkes, et TV-signal forstyrres av refleks. Lyden blir svakere over avstand. Lyset avbøyes. De fysiske media er aldri feilfrie. Derfor er dataforvrengningen et kjent fenomen for oss alle. Særlig i vårt århundre har de elektroniske media gjort problemet synbart for alle og enhver.
Dataforvrengning kan medføre informasjonsforvrengning. Jo større forvrengningen er, jo større er sjansen for informasjonsforvrenging. Men vi skal merke oss at det ikke finnes noen direkte proporsjonalitet mellom tap av datakvalitet og tap av informasjonskvalitet. Ved hjelp av regenerering kan en viss grad av dataforvrengning tolereres uten at informasjonen svekkes tilsvarende. Dette sørger regenereringen for. Vi kan dele dataforvrengningen inn i to typer:
a. Deterministiske forvrengninger
b. Tilfeldige forvrengninger
Typen av forvrengning avgjør hvilken metode som kan brukes for å regenerere dataene. En deterministisk forvrengning skjer etter et bestemt mønster. Ved å kjenne mønstret for denne forvrengningen kan signalet "forvrenges motsatt vei" slik at vi igjen står tilbake med det opprinnelige signal. Dette kalles å kompensere for forvrengningen. En vellykket kompensasjon avhenger av at mønstret for forvrengningen er kjent. Denne kan finnes ved at man forstår forvrengningsprosessen. Dersom man ikke forstår forvrengingsprosessen, står man overfor det samme problem som for tilfeldige forvrengninger (beskrevet under), men vi har den vesentlige fordel at dersom problemet løses, er det løst en gang for alle, da det er den samme forvrengningen som går igjen. La oss se på et par eksempler som beskriver deterministisk dataforvrengning:
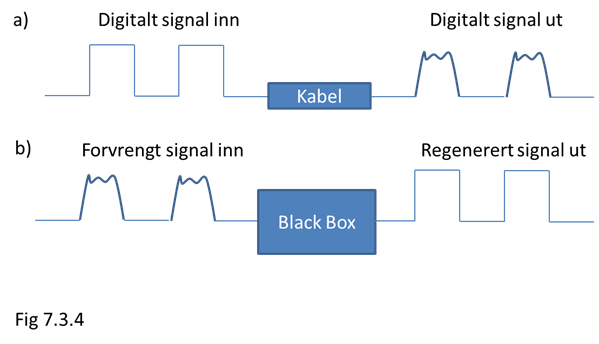
Innenfor datakommunikasjonen har man lenge visst at det er nærmest fysisk umulig å overføre rent digitale signaler over elektrisk kabel. Dette er fordi et digitalt signal (firkant-pulser, eller spenning av/på) inneholder uendelig høye frekvenser og disse kan ikke overføres via en vanlig kabel. (j.f.r. Fouriers teorem) En slik forvrengning er illustrert I fig. 7.3.4a. En slik forvrengning kan i teorien regenereres fullstendig. Ved hjelp av en boks, som "vet" formen på det digitale signalet, kan signalet opprettes til sin opprinnelige form. Dette er vist i fig. 7.3.4b.
Dette er grunnen til at digital lyd- og bildeoverføring kan få kvaliteter som langt overgår analoge overføringer. Ved å gjennomføre gjentatte regenereringer kan digitale signaler sendes over lange avstander uten at den opprinnelige informasjonen svekkes. Dersom et slikt medium fungerer perfekt kan det overføre 100 % korrekt informasjon. Dette er et ideelt medium.
Kryptering er et godt eksempel på deterministisk forvrengning av informasjon. Kryptering er koding av informasjon ved hjelp av hemmelige nøkler eller algoritmer slik at den blir utilgjengelig for uinnvidde. Denne teknikken har vært i bruk så lenge skriftspråkene har eksistert. Med tiden har metodene blitt mer og mer avanserte, likevel har de fleste koder frem til vår tid latt seg knekke. I vår tid er dette en ekspanderende vitenskap. Ettersom vi utveksler stadig mer elektronisk informasjon blir det stadig viktigere å unngå at sensitiv informasjon kommer i hendene på uvedkommende. Kryptering har tidligere tradisjonelt vært brukt til militære formål, men selv noe så dagligdags som vanlige banktjenester må beskyttes. Vi vil kanskje i årene fremover se en rivende utvikling på dette feltet.
Hoved problemet, eller utfordringen når det gjelder kryptering er at informasjonen skal forvrenges til det ugjenkjennelige og at kun mottaker skal ha de nødvendige midler til å regenerere den. Dette krever selvsagt at informasjonen må forvrenges på en entydig måte og den må kunne dekodes på en entydig måte; pr. definisjon deterministisk forvrengning. Til dette er det i dag utviklet mange sinnrike systemer. Disse skal jeg ikke komme inn på her. Det eksemplet vi skal se på her er fra romertiden. Det er den såkalte Cæsar-koden. Her er et budskap kodet med Cæsar-koden:
"L prujhq vocu yl wlo"
Slik som det står virker det umiddelbart meningsløst. Men nøkkelen er ganske enkel. Hver bokstav er skjøvet tre plasser frem, slik at A blir D, B blir E osv. Vi tenker oss at alfabetet går i sirkel slik at dette ikke skaper problemer for de siste bokstavene; Æ blir A, Ø blir B og Å blir C. Ved hjelp av denne koden kan vi raskt finne budskapet i koden:
"I morgen slår vi til"
Slike koder hvor hver karakter er fast substituert med en annen er imidlertid nokså enkle å knekke dersom språket har kjent. Den prosentvise fordeling av bokstaver har nemlig et bestemt mønster hvor hvert språk. Er budskapet langt nok vil det samme mønstret gjenta seg og på den måten kan man få ut hvilke karakterer som står for hvilke bokstaver.
"J+g +r u+nig i hva du si+r, m+n j+g vil til min død forsvar+ din r+tt til å si d+t"
Dette mønstret oppdages lett når vi kjenner alfabetet og det norske språk. Vi trenger kun å erstatte "+" med "e", så er dataene gjenopprettet.
Det siste er imidlertid et nokså idealisert tilfelle. Språklige deterministiske forvrengninger kan ofte ikke løses på en systematisk måte. Dersom jeg konsekvent erstattet alle j-er med g-er kan jeg ikke automatisk rette det opp igjen. Det er på grunn av at det fantes g-er fra før i teksten. Eksemplet ovenfor lar seg greit rette opp ved en rent mekanisk prosess. Det er en enkel oppgave for en datamaskin. Vi kan ikke bruke samme metoden for å rette opp utbyttinger av j-er med g-er. Vi vet nemlig ikke umiddelbart hvilke g-er som opprinnelig var j-er. Dersom en datamaskin skal kunne løse dette må den ha tilgang til ordliste. Det er regenerering av denne type som kreves når det er snakk om tilfeldige dataforvrengninger. Her trenges kunnskap om konteksten av informasjonen før problemet kan løses. For å beskrive dette er det enklest å bruke språket som eksempel.
Vi kan f.eks. miste et ord, eller en stavelse, men ut fra helheten kan de tapte data regenereres. Regenerering foregår på en bestemt måte. Ut fra forvrengningens nivå splittes dataene opp i enheter. Et språk kan deles opp i ord, da er det stavefeil som kan rettes opp, eller det kan splittes opp i setninger, da er det hele ord som kan rettes opp.
Helt generelt kan vi tenke oss at dataene må kunne splittes opp i to nivåer. Nivå A består av elementer på nivå B. A er med andre ord konteksten som elementene B inngår i. For å kunne regenerere forvrengninger på nivå B, må man ha kjennskap til det sett av mønstre nivå A kan bestå av. Ved å sammenligne det mønster elementene på nivå B danner, med alle kjente mønstre i A, kan man finne det mønstret som ligger nærmest. Deretter retter man opp de elementene på nivå B som avviker fra det utvalgte mønster. Betingelsene for en vellykket regenerering er:
1. Kjennskap til overordnede mønstre (konteksten)
2. At man gjetter på riktig mønster.
Regenereringen ligner i sin struktur på DIT-prosessen. Den bruker erfaringsnøkkelen til å regenerere dataene. Denne erfaringsnøkkelen består i kunnskap om et komplett sett av de mulige mønstre elementene på det overordnede nivå. Dette betyr ikke nødvendigvis at alle kombinasjoner ligger lagret, det kan like godt være kjennskap til regler for syntaks eller en forventning om hva informasjonen skal inneholde. Det er betingelse 1. Betingelse 2 avhenger av resursene og graden av forvrengningen. Prosessen har jeg kalt DDT-prosessen (Data Data Transformasjon).
La oss se på noen eksempler:
Gitt følgende setning:
"Arne har # seg i kneet"
Ved kjennskap til språket ser vi at setningen mangler et verb. Dette verbet må stå i fortid. Vi velger så mellom de verb som gir setningen mening. Kanskje hører vi Arne stå å hyle utenfor. Ved bruk av denne kunnskapen kommer vi raskt frem til at "#" skal erstattes med "slått". Dette er regenerering på setning-ordnivå.
Gitt følgende ord:
Pro¤eks@onstegni*g
Ved å sjekke ordforråd eller ordliste etter noe som ligner finner vi:
Projeksjonstegning
Dette er regenerering på ord-bokstavnivå.
Gitt følgende ord:
%ale
Her har vi mange alternativer: Tale, male, dale, gale, bale, hale osv. I dette tilfellet må vi ha mer kunnskap om sammenhengen før vi kan løse problemet. Dersom ordet forekommer i setningen: "Ole %aler gjerdet" kan problemet enkelt løses: "Ole maler gjerdet" er den absolutt mest sannsynlige løsning. Denne regenereringen har skjedd på setning-bokstavnivå.
Gitt følgende ord:
Hen..
Vi vet ikke om .. skal erstattes med en eller to bokstaver, så vi har mange muligheter: Hende, hendt heng, hengt osv. Vi kan ikke løse problemet på dette nivået, så vi går ett nivå opp:
«Gå opp og hen.. Hansen!»
Her gir begge setningene logisk mening:
«Gå opp og heng Hansen!»
«Gå opp og hent Hansen!»
Dette kan ikke løses før vi kjenner sammenhengen, eller den situasjonen setningen forekommer i. I Irans statsfengsel kan en feiltagelse her bety liv eller død. På en norsk bedrift ville det ikke vært tvil.
Vi ser at jo vanskeligere forvrengningen er, jo høyere må det overordnede nivå være for at dataene skal kunne regenereres.
Den neste type forvrengning som kan oppstå er resursforvrengningen. Dersom data og nøkkel er tilgjengelig trenges det ressurser som intelligens, tid, psykisk energi osv. for å kunne trekke ut ønsket informasjon. Dårlig intelligens, manglende psykisk energi kan føre til at f.eks. informasjonen kodes galt i IDT-prosessen, eller at informasjonen dekodes galt i DIT-prosessen. En av de viktigste former for resursforvrengning skyldes imidlertid mangel på tid. Dersom datamengdene er store kreves det tid for å få ut korrekt informasjon.
Ved å dobbeltsjekke noen summer har en revisor funnet ut at noen tall ikke stemmer. Han ber om en datautskrift for de tallene som ligger til grunn for summene. Datalisten blir på 8 meter. Av de mange tusen tallene som står der er kanskje ett, eller to feil. Alle andre tall er uvesentlige i denne sammenheng. Forholdet mellom datamengde og essensielle data er så stort at det kan ta flere uker å løse problemet. I tillegg må revisorens konsentrasjon være på topp hele tiden. I datamiljøet er dette blitt kalt for datadøden. Datamengden er så stor at man oppgir å finne informasjonen. I stedet gjetter man på den. (I dette tilfellet ville man laget et program som utførte revisorens algoritme for å avgjøre om et tall er riktig eller galt, deretter kunne maskinen ha sjekket alle tallene, mens revisoren tok en kopp kaffe)
Et annet eksempel på denne typen forvrengninger er uklart språk. Politikere blir ofte beskylt for å formulere seg uklart. Dette kan mange ganger ha gitt seg utslag i lovverket. Det er dette mange jurister lever av. I USA er man enda ikke enige i om dødsstraff er grunnlovsstridig. Hva mente de ærverdige herrer fra den gang, tenkte de på det i det hele tatt? Slike problemer lar seg også løse dersom man kjenner helheten. Men gjør man det?
Se også her og her, for senere videreutvikling av dette temaet. Denne typen informasjonsforvrengning skyldes uoverensstemmelse mellom nøklene i IDT- og DIT-prosessene. På lavere nivå vil en slik forvrengning lett kunne oppdages.
Opphavet til slike forvrengninger ligger pr. definisjon i DIT-prosessens nøkkel. Dataene foreligger jo hos DIT, kodet etter en bestemt kode og hittil har ingen forvrengning skjedd. Forvrengingen skjer først idet DIT trekker frem gal nøkkel. På språknivå er denne forvrengningen bort imot total. Jeg får f.eks. intet ut av å høre italiensk, eller å lese kinesiske skrifttegn. Dansk forstår jeg kanskje 60 % av, resten legger jeg til ved regenerering. Men problemer vil alltid oppstå og disse forvrengningene skyldes avvikende protokoll-nøkkel. Vi har tidligere snakket om begrepsforvirring. Det er en typisk protokoll-nøkkel-forvrenging som kan være vanskelig å oppdage.
Erfarings-nøkkelforvrengning er en interessant type forvrengning. Denne oppstår på grunn av manglende kunnskap, eller feil kunnskap. Det kan gjelde kunnskap om fysiske prosesser, eller det kan gjelde kunnskap om dataenes opphav.
I sin ytterste konsekvens innebærer dette at kunnskap ikke er mulig dersom vi mangler forhåndskunnskap til å fortolke en signalstrøm. Vi er altså avhengig av kunnskap for å kunne forstå kunnskap. All fortolkning krever forhåndskunnskap. Og dersom forhåndskunnskapen er feil, blir fortolkningen tilfeldig. Men hvordan kan mennesket i det hele tatt begynne å forstå verden? Svaret må ligge i at vi er født med en rekke grunnleggende forestillinger som fungerer som en slags kunnskapens medfødte startkapital. Disse forestillingene er helt grunnleggende, som forestillinger om tid og rom og om kausalitet. På data-språk ville jeg si at dette er noe som ligger «hardkodet» i oss og som gjør det mulig for ethvert individ å komme i gang med erkjennelse.
Den gamle seiglivede oppfatningen om at solen kretset rundt jorden skyldes nøkkelforvrengning. Manglende kunnskap om årsaken til det observerte førte til gal nøkkel. Fakta ble galt tolket.
En mann kommer springende og roper at huset ditt brenner. Du kommer deg ut i en fart, men oppdager raskt at ingen fare er på ferde. Du har da brukt feil nøkkel fordi du forvekslet informasjonens opphav. Du trodde budskapet hadde sin opprinnelse i husets tilstand, og at mannen bare var et medium. I stedet var det mannen selv som var opphavet til informasjonen og da sier den noe helt annet. Den kan fortelle at mannen har en merkelig form for humor, eller at han har vrangforestillinger.
Dette eksemplet er et klart eksempel på forveksling av hvilken IDT-prosess som var opprinnelsen til informasjonen. Dette fører til gal tolkning av virkeligheten.
Ved observasjon av naturfenomener er vi avhengig av tidligere kunnskap for å kunne tolke dataene riktig. I vikingetiden ble f.eks. lyn og torden oppfattet som at Tor kastet med hammeren. Dette forutsatte kjennskap til Tor, og hammeren hans. Dette var nøkkelen som lå til grunn for tolkning av informasjonen.
Kausalitet betyr årsaksforhold. Kausalitetsforvrengning er den forvrengning som oppstår ved at det eksisterer ukjente årsaks-forhold mellom de forskjellige elementene i informasjons-prosessen. Der vil alltid eksistere et årsaksforhold fra IDT-prosessen til media, og fra media til DIT-prosessen. Dette årsaksforholdet er en forutsetning for at informasjonsoverføring skal være mulig. Men dersom der eksisterer et årsaksforhold den motsatte veien, fra DIT, til media, fra media til IDT, har vi straks problemer. Den informasjon som mottas fra IDT-prosessen er da påvirket av media, og er derfor ikke det den skulle ha vært dersom media ikke hadde vært der. La oss ta et eksempel:
Måling av spenning i kretser med høy resistans.
De fleste av oss vet hva elektrisk spenning er. Forholdet mellom strøm spenning og resistans er gitt i Ohms lov:
![]()
Dersom vi tenker oss to motstander koblet i serie hvor det går en bestemt elektrisk strøm. (se fig 7.3.5) Vi tenker oss at disse motstandene har høy resistans. Vi ønsker informasjon om U2 som er spenningen over R2. Til dette bruker vi et voltmeter. Vi kobler voltmetret som vist på figuren.
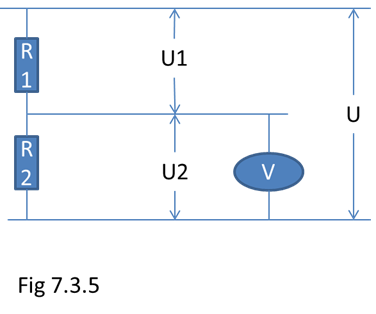
Nå er det slik at voltmetret selv er en resistans, derfor trekker det strøm fra kretsen. Men da går det mer strøm gjennom R1, og spenningsfallet over denne U1 øker. Vi tenker oss at U er konstant, derfor minker U2. Resultatet er at den spenningen voltmetret måler er mindre enn den er i virkeligheten, altså når voltmetret ikke er tilkoblet. Dersom R2 har høy resistans og voltmetret er av den vanlige analoge typen, hvor resistansen ikke særlig høy, kan en slik måling gi et fullstendig galt resultat.
Dette gale resultatet er ikke årsaket av dataforvrengning. Voltmetret, som er media, gir riktig utslag. Der behøver heller ikke eksistere noen resurs eller nøkkelforvrengning. Vi har kunnskap nok til å tolke utslaget på voltmetret riktig. Vi observerer da også den faktiske tilstanden i kretsen. Men det er den tilstanden kretsen er i akkurat i det øyeblikket den blir målt. Det er ikke den tilstanden den vanligvis er i. Dersom vi ikke kjenner dette forholdet blir vi ledet til å tro at dette er kretsens normale tilstand. Dermed her det skjedd en forvrengning.
Kausalitetsforvrengningen er vel kjent i vitenskapen. Et av vitenskapens mest grunnleggende prinsipper er skillet mellom subjekt (observatør) og objekt (det observerte). I praksis får vi imidlertid problemer her. Innenfor atomfysikken og særlig innenfor kvantemekanikken er kjennskap til denne problemstillingen av fundamental betydning for tolkning av resultatene og for måleoppstillingen i det hele tatt.
En annen dimensjon av denne problemstillingen ser vi inne psykologien. Vi påvirkes av de spørsmål vi får. Graden av påvirkning avhenger selvfølgelig av måten spørsmålet er stilt på. Men psykologien bygger sin kunnskap på nettopp det å spørre ut folk. Dette er et fundamentalt problem som også psykologien må leve med.
I all vitenskap som har med måle-teknikk å gjøre har man utviklet metoder for å håndtere usikkerhet. Dette gjelder spesielt fysikken. Ingen målinger gir eksakt riktige verdier. Korrekt skal slike målinger oppgis med usikkerhetsmarginer f.eks. 5 +- 0.2 V. Vi vet at størrelsen skal ligge innenfor et gitt intervall. Viten om denne usikkerheten avgjør bl.a. hvor mange desimaler det gir mening i å ta med i et svar, etter en utregning hvor slike usikkerheter inngår. I fysikken har det vært lett å innse at måleresultater aldri kan bli eksakte. Verre er det å innse at all informasjon kan være usikker. Når vi nå har sett litt mer generelt på dette med informasjonsforvrengning, er det lett å innse at dette er problemer som egentlig angår all informasjon. Når vi skal vurdere usikkerheten til informasjonen må vi vurdere muligheten for forvrengninger fra informasjonens opprinnelse til den når min bevissthet. Det første usikkerhetsmomentet er selvfølgelig opprinnelsen. Dersom vi regner oss som sikre på den må vi se på selve overføringen, hvor sikker er vi på den? Vi har tidligere snakket litt om media. Vi skal nå utvide media-begrepet til å omfatte alle typer informasjonsforvrengning. Et slikt medium kan godt være et menneske, og et menneske kan godt gjøre seg skyldig i alle typer forvrengninger. Media kan splittes opp i enkeltledd, disse kan splittes opp i nye ledd osv. Som før nevnt kan vi her splitte opp i det uendelige, men av praktiske årsaker splittes media opp i logiske ledd som bidrar til tap av informasjon. Alle andre ledd regnes for å være ideelle media, det vil si de overfører 100 % korrekt informasjon. De logiske leddene bidrar alle mer eller mindre til tap av informasjon. De enkelte leddene kan nå sette sammen til et nettverk som overfører informasjonen. Nettverket kan logisk splittes opp i serie og parallell informasjonsoverføring. Serieoverføring er kjeder av informasjonsoverføringsledd. Parallell overføring er overføring via forskjellige kanaler. Ved å angi tapet for hvert enkelt ledd i prosent kan vi beregne det totale tapet i prosent. Fig 7.3.6a og 7.3.6b viser prinsippet for henholdsvis serie og parallell informasjonsoverføring.
Ved serieoverføring vil hvert enkelt ledd bidra til tap av opprinnelig informasjon. Jo flere ledd, jo større tap. Dersom vi kjenner bidraget for hvert enkelt ledd kan tapet beregnes etter formelen for seriell informasjonsoverføring.
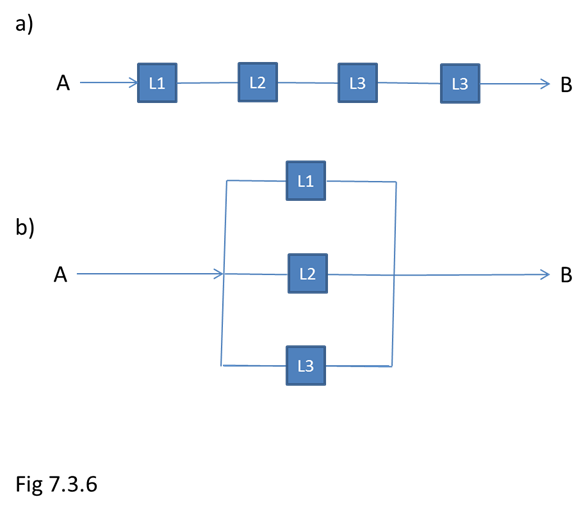
Ved parallelloverføring vil hvert enkelt ledd styrke informasjonspåliteligheten. På samme måten som ved seriell overføring kan det totale tap beregnes dersom hvert enkelt ledd er kjent.
Formlene for tap ved parallell og seriell informasjonsoverføring:
Serie:
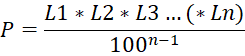
Parallell:
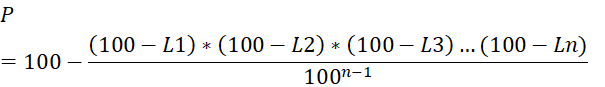
P = Pålitelighet i prosent
L = Pålitelighet av et ledd i prosent
n = antall ledd
Disse formlene har for meg bare teoretisk verdi. Overgangen mellom data og informasjon er subjektiv, den avhenger av hvilken informasjon vi ønsker ut av dataene. Dette medfører at informasjonstapet egentlig avhenger av øynene som ser. Da informasjonstapet egentlig er subjektivt er det umulig å komme frem til objektive tall på dette. Formlene forteller bare generelt hvordan informasjonspåliteligeten styrkes eller svekkes som følge av det nettverk den har passert. I praksis regner vi likevel med at dette er tilfelle. Vi stoler mer på en hendelse som er beskrevet i fem aviser samtidig, enn om den kom til oss som et rykte. Et rykte vet vi har passert mange ledd, vi kan derfor aldri feste lit til det. Men dersom fem aviser skiver om samme hendelse og alle er førstehandsbeskrivelse, stoler vi som regel blindt på at informasjonen må være riktig.
Ved å gjøre noen sonderinger på disse formlene kan vi finne frem til noen enkle regler angående informasjonspålitelighet.
For å bli dus med formelen tar vi først et praktisk eksempel:
Vi ser litt på eksemplet med overføring av et TV bilde. Vi
regner det todimensjonale bildet som avgrenses av kameralinsen som 100%. Alle leddene er i serie ,derfor bruker vi formelen for serieoverføring. Vi regner med overføring fra kamera mottar lyset, til lyset når øyet. Jeg velger følgende tall:
Kamera 90 %
Mikser 99 %
Forsterker 99 %
Sender 95 %
Omformer 90 %
Antenne 90 %
Tv 90 %
Til svar får jeg 61,1 %. Tolkningen av et slikt svar må selfølgelig gjøres ut fra sunn fornuft. Da vi i dette tilfellet kun hadde med naturlige media å gjøre betyr dette bare at kvaliteten på det overførte bildet er redusert med ca. 39 %, og det er faktisk et bra TV bilde. Men vi ser også at det totale tapet er mye i forhold til hvert enkelt ledd.
La oss tenke oss at senderen, på grunn av feil, sendte med 50 % av vanlig effekt. Vi vil da sitte igjen med bare 32 % av den opprinnelige informasjonen. Hvis den brøt helt sammen blir den overførte informasjonen 0 %.
Det enkelte ledds tap kan derfor ha enorm betydning på det totale resultat. Hvis det i en seriell overføring av informasjon forekommer ledd av typen brudd, eller ideell, gjelder følgende regler:
Hvis det i en seriell informasjons overføring forekommer et ledd som overfører 0 % informasjon (brudd) er, den mottatte informasjonen verdiløs som beskrivelse av den opprinnelige kilde.
Hvis det i en seriell informasjons overføring forekommer et ideelt ledd, (100 %) er dette leddet uten betydning for eventuelle tap i overføringen.
Et eksempel på dette kan være at brannalarmen går samtidig som du lukter røyk. Hvis du like etterpå ser flammer, ja da er du sikker på at det brenner. Du har mottatt informasjon fra tre uavhengige kilder og alle bekrefter hverandre. Hvis nå brannalarmen var upålitelig eller at den ikke virket i det hele, ville du da være sikker? selvfølgelig ville du det, du ser jo flammene og du kjenner røken. I dette eksemplet mottar du informasjon fra tre forskjellige ledd. Hvis det blir brudd i et av leddene vil du likevel kunne stole på den informasjon du mottar er korrekt. Hvis det i en parallell informasjonsoverføring forekommer ideelle ledd eller brudd, gjelder følgende regler:
Hvis det i en parallell informasjonsoverføring forekommer et ideelt ledd, har vi en ideell informasjon, dvs. den informasjonen vi mottar beskriver en eksakt sannhet.
Hvis det i en parallell informasjonsoverføring forekommer et ledd av typen brudd, skal ikke dette leddet tas med i beregningen av tap i informasjonen.
I tillegg til disse fire reglene har jeg satt opp enda en viktig regel. Hvis vi i eksemplet med overføring av et TV bilde fikk et ledd av typen brudd, har vi da mistet all informasjon? I følge de foregående regler, har vi det. Men det er ikke helt riktig, vi har kun mistet informasjonen som skulle beskrive kilden. I stedet mottar vi informasjon om at noe er galt. Vi fikk kanskje vite at senderen var ute av drift eller at TV en røk. Vi har altså mottatt informasjon om en annen kilde enn den forutsatte. Kilden er 0 % leddet.
Jeg så en gang et TV program om to amerikanske forskere, som bl.a. hadde gjort store oppdagelser angående kolesterol i blodet. De lagde stadig nye teorier og utførte eksperimenter for å bekrefte eller avkrefte disse. Det er klart at ikke alle eksperimenter ga de resultater de hadde tenkt seg, dette kunne ofte være en skuffelse for dem. Men den ene av dem pleide alltid å ta det med et smil og si: «That’s a positive negative». Eksperimentet ga informasjon om at de tok feil, og det er hele poenget: all informasjon er informasjon om noe.
All informasjon er reell informasjon.
Politietterforskere sier ofte at barn er de beste vitnene. Barn gjengir det de har sett, mens voksne ofte gjengir tolkningen av det de har sett. Mesteparten av den informasjonen jeg mottar har tidligere passert andre mennesker. Mennesker og dyr er underlagt de samme lover for informasjonsforvrengning som mekaniske ledd. Mennesket forvrenger informasjonen på de samme måter som før nevnt:
· Det hører eller ser feil (dataforvrengning)
· Det tolker informasjonen feil (nøkkelforvrengning)
· Det gjetter feil fordi det ikke har tid til å undersøke (resurs forvrengning)
· Det stiller ledende spørsmål (Kausalitetsforvrengning)
Dataforvrengning er en utelukkende mekanisk forvrengning. Den skjer på grunn av direkte svikt i media. Nøkkelforvrengning og resursforvrengning krever kunstig- (datamaskiner) eller naturlig- (levende skapninger) intelligens for å kunne oppstå. Dette er jo fordi forvrengningen skjer i selve tolkningsprosessen (DIT). Kausalitetsforvrengning har det kun mening i å snakke om i forbindelse med levende skapninger som erkjennende vesener. Fordi det er snakk om aktivitet for å skaffe informasjon til veie. Så langt vi vet, er det bare oss levende vesener som bedriver den slags aktiviteter.
Vi kan derfor her snakke om kunstig informasjonsforvrengning. Med kunstig, mener jeg, at der alltid er en eller annen form for intelligens innblandet i prosessen. Men for å gjøre bildet komplett må vi i forbindelse med levende skapninger innføre en ny type kunstig informasjonsforvrengning, det er den subjektive, som kan være alt fra en skjev eller farget fremstilling til ren løgn. Ofte tenderer vi til å se informasjonen gjennom et farget lys. Er sannheten slik vi vil den skal være, eller er den iblandet med våre egne ønskedrømmer. Dette behøver ikke å være bevisst. Ubevisst kan vi søke å oppnå en personlig gevinst ved å forstå noe på en mer farget måte, eller det kan være at sannheten er for ubehagelig å forholde seg til. I slike tilfeller vil våre følelser forurense virkelighetsoppfatningen. Det kan som sagt være både bevisst og ubevisst. I den grad det er bevisst kan en videreformidling karakteriseres å være en løgn.
Subjektivforvrengning oppstår alltid i IDT-prosessen (hos avsender).
Inngående informasjon blir blandet med tidligere kunnskap, eller direkte erstattet, eller holdt tilbake. Her er det mange muligheter. I de tilfeller det er snakk om blanding eller erstatning, må det en nøkkelforvrengning til i DIT-prosessen (hos mottaker) for at løgnen skal lykkes. DIT-prosessen tar rett og slett feil av informasjonens kilde. Da løgnen egentlig består av blandinger av de nevnte faktorer, er det umulig for DIT-prosessen å tolke informasjonen på riktig måte. Løgnen har flere kilder. Sannhet og fantasi settes sammen i skjønn forening, i den hensikt å villede. Det er derfor naturlig å snakke om subjektiv-forvrengingen som en egen type forvrengning, ved siden av nøkkelforvrengingen. I dyreverden er løgn, eller desinformasjon, et utbredt middel til bl.a. beskyttelse av unger og til jakt. Hos mennesket er denne evnen absolutt mest utpreget. Dette skyldes menneskets enorme fantasi. Mennesket er rett og slett ekspert på å lyve. Vi skal likevel merke oss at det er samme grunnleggende motiver for løgn som driver både dyr og mennesker, det er samme forvrengningstype. Her er det bare snakk om gradsforskjeller. Løgnen er et redskap, som brukes i samspillet med andre skapninger, for å fremme individets egne interesser, ofte på bekostning av andre. Det er derfor jeg har valgt å kalle denne type forvrengning for subjektiv-forvrengning.
Noen spesielle egenskaper ved subjektiv-forvrengningen:
En person har begått underslag og prøver å skjule det. Dersom du spør denne personen hva klokken er, eller hvor han bor, er det liten tvil om at svaret er riktig. Men dersom vi begynner å spørre han inngående om regnskapet i firmaet, kan vi da være så sikker? I det ene tilfellet overførte han informasjonen nesten 100 % korrekt. I det andre tilfellet kan informasjonen være forvrengt til det ugjenkjennelige. M.a.o. informasjonsforvrengingen er ikke konstant, den avhenger i høy grad av innholdet i den overførte informasjon.
Man kan stole mer på noen mennesker enn på andre.
Vi kjenner alle til hvordan en fjær kan bli til ti høns. Et rykte kan bygge seg opp til et helt sagn. Selv om den opprinnelige informasjonen forsvinner helt, kan informasjonsvolumet øke. Vi sitter da igjen med utelukkende desinformasjon.
Da informasjonsforvrengninger med mennesket som medium kan ta så mange forskjellige former skulle man tro at det ikke var mulig å komme frem til generelle lover for påliteligheten av slik informasjon. Det er riktig i den grad at det er umulig å kvantifisere påliteligheten nøyaktig. Likevel må de samme lovene som gjelder for mekanisk overføring, også gjelde for mennesker. De fleste av oss har vært med på den såkalte hviskeleken, der en beskjed passerer mange mennesker i serie. Svært ofte skal det ikke mange leddene til før forvrengningen blir synbar. Jo flere ledd, desto større forvrengning. Loven for seriell informasjonsoverføring gjelder fortsatt. Lignende resonnementer gjelder også for parallell informasjonsoverføring.
Vi har kanskje flere sanser en «de fem vinduene til sjelen» som Aristoteles definerte. Felles for alle sansene er at de omdanner ytre stimuli til elektriske signaler som hjernen kan forstå. Beskjedene fra sansene blir transportert via nervetråder eller med hormoner som budbringere. Nyere forskning viser at bare 1 % av alle inntrykk når frem til hjernen. Resten filtreres bort fordi de er uvesentlige. Vi vet også at veien er lang og signal-behandlingen meget omfattende fra de signalene hjernen sansene sender til det vi bevist oppfatter. 100 millioner synsceller registrerer lyset. Alle impulsene sendes til hjernen via synsnerven. De elektriske impulsene blir ledet etter bestemte ruter i hjernen, nemlig synsbanene. De går til synsnevekrysningen, hjernestammen og bak til selve synssentret, der den bevisste synsopplevelsen foregår. En god del av synsopplevelsene er imidlertid bare bløff. Hvis vi ser nøye etter på f.eks. et fargefjernsyn ser man at bildet består av en rekke små punkter. Punktene har bare tre forskjellige farger, rødt grønt og blått. Ved å variere styrken på de tre fargene kan alle andre farger fremkomme. Når man ser bildet på avstand fremstår det som en skarpt avgrenset enhet. Dette kommer av at hjernen er i stand til å koordinere en stor mengde sanseinntrykk slik at de danner en enhet. Sansecellene i seg selv gir ikke så skarpt syn. Et stort antall små punkter omdannes til hele bilder i synsbarken, men det er ikke punktene som gir bildet. Synsopplevelsen dannes under påvirkning av hjernen selv. De dannes ut fra en kombinasjon av forventning om hvordan bildet skal se ut, tidligere erfaringer og ut fra hvordan områdene rundt bildet ser ut. Det vi ser har altså allerede før det når vår bevissthet vært gjenstand for omfattende signalbehandling. Denne signalbehandlingen øker billedkvaliteten ved hjelp av tolkning og regenerering. Det er tolkning på underliggende nivå, som utnytter tidligere erfaring og sannsynligvis en god del medfødt kunnskap om hvordan verden skal se ut. Lignende funksjoner gjelder også for hørselen. På denne måten kan vi gå ut fra at sansene er et meget komplisert apparat som ut fra input og tidligere erfaring gir oss et optimalisert bilde av verden rundt oss. Forvrengningen her er meget lav.
Men når vi skal se på mennesket som informasjonsoverforingsmedium er dette bare halve sannheten. Den informasjonen mennesket mottar skal gis videre. Dette skjer gjennom kommunikasjonskanalene, og her er språket sentralt. Men før sanseopplevelsen kommer så langt som til språk, passerer den et meget viktig ledd. Nemlig hukommelsen. De sanseinntrykk vi mottar, danner umiddelbare mønstre i hjernen. Disse mønstrene representerer den bevisste opplevelse. Dette kalles persepsjon. Når du husker opplevelsen fremkaller hjernen en kopi av dette mønstret. Vi vet at persepsjonen foregår med en bestemt frekvens. Denne frekvensen avgjør din tidsoppfatning. Enkelte dyrearter har mye større frekvens enn vi. Dette gjør at de oppfatter tiden som lengre en vår tid. En flue vil f.eks. oppfatte oss mennesker som meget langsomme skapninger. Selv om dens levetid er mye kortere enn vår, føles den sannsynligvis som like lang. I hukommelsen «logges» hvert eneste sanseinntrykk. Derfor opplever vi tid. Det gamle spørsmålet om tidens eksistens uavhengig av mennesket er derfor meningsløst. Den livløse verden består bare av øyeblikk. Disse øyeblikk «logges» av vår hukommelse, settes sammen i kronologisk rekkefølge. På denne måten blir vi i stand til å oppleve påfølgende begivenheter. Vi får en fortid. Ved å finne regelmessigheter i de påfølgende begivenheter kan vi regne oss frem til fremtidige begivenheter. Vi får en fremtid. Dette er tiden. En enkel menneskelig abstraksjon, som er en naturlig følge av hukommelsen. Men hvordan kan vi skille et direkte sanseinntrykk fra hukommelsens kopi? Forskjellen ligger sannsynligvis i styrken på inntrykket. Men det å logge tusenvis av sanseinntrykk hvert eneste sekund må nødvendigvis kreve meget stor lagringskapasitet. Freud hevdet at vi egentlig aldri glemte noen ting. Inntrykkene blir liggende der. Her ligger det nok en mengde ubesvarte spørsmål. I praksis vet vi imidlertid at hukommelsen ikke er perfekt. Vi glemmer. Og sannsynligvis er denne glemselen helt nødvendig for at hjernen skal kunne handtere så store datamengder optimalt. (ser i denne omgang bort fra fortrenginger.) Men her finner vi en meget viktig kilde til forvrengning, nemlig den menneskelige hukommelse. All informasjon et menneske overfører går via hukommelsen. Denne forvrengningen må høre inn under begrepet dataforvrengning da den sannsynligvis skyldes den fysiske måten hjernen arbeider på.
Menneskets evne til å utrykke seg , er sannsynligvis mye dårligere enn sansenes evne til å gi inntrykk. Når et menneske forteller deg hva det har sett, sitter du som regel igjen med et inntrykk ganske forskjellig fra det opprinnelige sanseinntrykk. La oss si at noen beskriver en mann for deg. Du får vite hårfarge, øyenfarge, høyde, stemmeleie, hodeform osv. Du setter da sammen disse beskrivelsene ved hjelp av tidligere egne sanseinntrykk. På denne måten danner du deg et bilde av mannen. Men dette bildet kan ikke annet enn bestå av dine tidligere sanseinntrykk. Et menneske kan aldri gi deg det ekte synsinntrykket ved hjelp av språk. Når du senere får se mannen ser han sannsynligvis mye annerledes ut enn du hadde forestilt deg. Denne forvrengningen skjer først og fremst på grunn av sansetransformasjon. I dette tilfelle brukes lyd for å beskrive synsinntrykk. Dersom man kan tegne har man mye større mulighet til å formidle mannens utseende. Har du noen gang hørt ren verbal beskrivelse av musikk? Det lengste vi kommer her er sannsynligvis noter. Poenget er at slik sansetransformasjon alltid vil svekke informasjonen. Dette kommer inn under resursforvrengingen. Man mangler rett og slett resurser til å utrykke inntrykket. (man kan ikke tegne)
Når det gjelder nøkkelforvrengning skjer denne ved at man har tendens til å gjengi sin egen tolkning av inntrykket i stedet for inntrykket i seg selv. En ideell journalist må være fri for denne type forvrengning. I dagens aviser er dessverre ikke denne regelen lengre tatt på alvor. Men det er særdeles vanskelig å gjengi informasjon ubesmittet av egne tolkninger. Når vi glemmer, glemmer vi detaljene først. Vi sitter igjen med helhetsinntrykket. Når dette skal gjengis regenerer vi detaljene. Dette gjør vi ved hjelp av konteksten. Dersom vi har tolket feil, setter vi inntrykket inn i gal kontekst, dermed blir de regenererte detaljene også feil.
Vi mennesker er de mest kunnskapssøkende vesener på vår planet. Mye av et småbarns aktivitet er nettopp drevet av nysgjerrigheten. Men ved vår aktivitet deltar vi i den verden vi observerer. Spesielt i vår omgang med andre mennesker, påvirker vi ved vår væremåte. Vi vet m.a.o. aldri hvordan det menneskelige miljø rundt oss ville ha vært dersom vi selv ikke eksisterte. Dette gjør at vi ofte trekker forhastede slutninger om miljøet rundt oss.
Som en oppsummering kan vi si at mennesket er et høyst upålitelig informasjonsoverføringsmedium. Dette viser all praksis. Dette gjelder på tross av at sansene våre er noe av det mest fantastiske som finnes. De største kildene til upåliteligheten finnes i:
1. Hukommelsen (dataforvrengning / nøkkelforvrengning)
2. Evnen til å utrykke seg (resursforvrengning)
3. Viljen til å snakke sant (subjektiv forvrengning)
4. Den aktive deltagelse i det observerte. (Kausalitetsforvrengning)
Et nettverk består av noder og relasjonene mellom dem. Relasjonene består i denne sammenheng av fysiske dataoverførings-media, og nodene er mennesker. Mennesket er et flokkdyr. En flokk med mennesker, eller ett folk kan sies å ha felles hukommelse. Denne hukommelsen sitter spredt et nettverk av mennesker. Vi skal nå se på hvilke krefter som virker på informasjon som passerer et slikt nettverk. Når vi snakker om at et slikt nettverk fungerer som et medium tenker vi oss logisk en sender og en mottaker på hver side av nettverket. Men her skal vi merke oss at både sender og mottaker er en del av nettverket. I et slikt nettverk er hvert enkelt menneske, eller hver node både sender mottaker og medium. I vårt daglige liv er vi stadig i kontakt med andre mennesker. Det sett av relasjoner vi har til andre mennesker i løpet av en periode er unikt. Dersom du ikke lever i et svært isolert samfunn er det ingen andre enn akkurat du som kjenner akkurat den kombinasjonen av mennesker som du gjør. Tenk etter, og du oppdager at det er sant. Via disse kontaktene mottar du, behandler, tolker og sprer informasjon. I en kort periode kan kanskje et slikt nettverk virke ganske konstant. Du har de samme vennene. Du har de samme arbeidskameratene. Og informasjonen som spres gjelder nåtiden. Du er en del av et sanntidsnettverk. Men etter som tiden går endrer mønstret seg. Noen flytter, noen dør, nye kommer til. I løpet av generasjonene skiftes noder og relasjoner totalt ut. Men dette skjer dynamisk. Derfor bevares informasjon i nettverket fra generasjon til generasjon. En kultur har felles hukommelse. Sett i dette perspektiv er det nettverk du er en del av et generasjonsnettverk. Ett generasjonsnettverk overfører informasjon fra generasjon til generasjon. Vi skal i første omgang konsentrere oss om muntlige overleveringer. Her gjør alle typer forvrengning seg gjeldende. Men noen krefter motvirker forvrengningen, andre medvirker. De krefter som motvirker forvrengningen er først og fremst felleshukommelsen. Hele historien finnes spredt over mange noder. Der forvrengningene forekommer vil det oppstå avvik. Ved parallell informasjonsoverføring vil disse avvikene kunne avdekkes og regenereres. I mange tilfeller vet man ikke hva som er avvik og hva som er ekte. I slike tilfeller må man jobbe med alternative muligheter inntil man finner andre kriterier, f.eks. arkeologiske utgravninger, som kan eliminere et eller flere alternativer. Dersom man ikke finner slike bevis eller motbevis, er disse deler av historien blitt høyst usikre. Men stadig vil man sitte igjen med basisinformasjon som fortsatt er sammenfallende i hele nettverket. En slik basisinformasjon kan f.eks. være at Jesus har eksistert. Det må regnes som ganske sikkert. Men informasjonen om Jesu himmelfart knytter det seg adskillig større usikkerhet til, og barndomshistoriene i Thomas evangelium regnes som usannsynlige. Jo større detaljrikdom desto større avvik, og desto mindre sannsynlighet. Hukommelsen i et nettverk virker derfor på samme måten som i en hjerne. Det er helheten som huskes, detaljene blir mer og mer uklare. Den andre faktoren som virker mot informasjonsforvrengingen er en mennesketype som jeg har kalt for tradisjonalisten. Det er en person som legger sin flid i å bevare tradisjonen og føre den videre. Han virker som en kopimaskin fra far til sønn. Han overleverer historien, til sin sønn ,nøyaktig slik som han fikk den av sin far. Intet legges til intet trekkes fra. Den beste måten å gjøre dette på er å lære historien utenat. Denne metoden er f.eks. brukt av jødene. Også vår kultur har benyttet seg av dette. Min foreldregenerasjon måtte lære samlevers, bud og trosbekjennelsen utenat. Selv måtte jeg lære budene. I dag er mye av denne utenattpuggingen overflødig i denne sammenheng. Vi har jo det skrevne ord. Men i de kulturer hvor analfabetismen er sterkt utbredt må jo slik utenattpugging være alfa omega for bevaring av tradisjonen. Det finnes nemlig meget sterke krefter som arbeider med forvrengningen. Det er først og fremst påtrykk utenfra, og den kreative innenfra. Ingen kultur er isolert. Og i kontakt med andre folkeslag blandes tradisjonene. Fremmede tradisjoner vil ubønnhørlig trenge seg inn å blande seg med egne tradisjoner. Men hvem er blanderen? Det jeg kaller for kreativisten. Kreativitet har mye med legning å gjøre, men mest har det med holdning. Utallige motiver driver den kreative. Det kan være makt, sensasjon, fantasi, opprør, kunnskapstørst, hensiktsmessighet. Disse motivene kan også tradisjonalisten ha. Men kreativisten setter disse motivene høyere enn tradisjonen. Han plukker gjerne med seg det beste fra tradisjonen, legger til litt selv og blander med stoff fra andre kulturer. Kreativisten ønsker å forbedre tradisjonen. Men denne forbedringen har en pris: kulturarven svekkes. Denne prisen er for høy for tradisjonalisten. Her ligger en naturlig konflikt mellom mennesker. Men begge krefter er nødvendig for samfunnet. Tradisjonskreftene sørger for kontinuitet og stabilitet i samfunnet. De kreative kreftene sørger for vekst og utvikling.
 I fig 7.3.7 har jeg forsøkt å
vise de krefter som motvirker informasjonsoverføringen i et
generasjonsnettverk. En hendelse hadde fire øyenvitner. Disse sprer
informasjonen inn i nettverket f.eks. på en slik måte som vist i figuren. De
røde sirklene er kreativistene. Jo tidligere en kreativist befinner seg i
nettverket desto større blir skaden. Slik jeg har tegnet det, er ingen av
versjonene som når nettverket upåvirket av kreativister. Inne i nettverket
sprer informasjonen seg og blir blandet med påtrykk utenfra. I enden av
nettverket tenker vi oss en mottaker. Han har ingen mulighet for å nå tilbake
til øyenvitnene, de er forlengst døde. Mottakeren får tre parallelle versjoner.
Sannsynligvis kan avviket nå være så stort at han kan oppfatte dem som
forskjellige historier. På denne måten splittes historien opp og blandes med
andre historier. Dette fører til at all informasjon som nettverket overfører
blir pulverisert. Man søker selvfølgelig stadig å finne metoder for å
regenerere slik informasjon. Et sagn om at en by har eksistert kan f.eks.
bekreftes med arkeologiske utgravninger. Man kan også søke å finne tilbake til
opprinnelige sagn ved å trekke ut de fragmenter som kan spores tilbake til ytre
påvirkning. Men dette er et møysommelig puslespill, og det kan aldri bli
sikkert. Påvirkning går ofte begge veier, og hvordan kan man bekrefte hvem som
har påvirket hvem? David Hume kom frem til at sannhetsverdien i slike sagn
utelukkende kunne fastsettes i rimeligheten. Dersom sagnet strider mot personlig
erfaring og fornuft, måtte det avskrives. Personlig vil jeg ikke gå så langt.
En avskrivning er 100 % sikker i negativ retning. M.a.o. må jeg ha 100 % bevis
for en slik avskrivning, og i de fleste tilfeller har vi ikke det. Det eneste
jeg kan gå med på er å senke sannsynligheten til et minimum.
I fig 7.3.7 har jeg forsøkt å
vise de krefter som motvirker informasjonsoverføringen i et
generasjonsnettverk. En hendelse hadde fire øyenvitner. Disse sprer
informasjonen inn i nettverket f.eks. på en slik måte som vist i figuren. De
røde sirklene er kreativistene. Jo tidligere en kreativist befinner seg i
nettverket desto større blir skaden. Slik jeg har tegnet det, er ingen av
versjonene som når nettverket upåvirket av kreativister. Inne i nettverket
sprer informasjonen seg og blir blandet med påtrykk utenfra. I enden av
nettverket tenker vi oss en mottaker. Han har ingen mulighet for å nå tilbake
til øyenvitnene, de er forlengst døde. Mottakeren får tre parallelle versjoner.
Sannsynligvis kan avviket nå være så stort at han kan oppfatte dem som
forskjellige historier. På denne måten splittes historien opp og blandes med
andre historier. Dette fører til at all informasjon som nettverket overfører
blir pulverisert. Man søker selvfølgelig stadig å finne metoder for å
regenerere slik informasjon. Et sagn om at en by har eksistert kan f.eks.
bekreftes med arkeologiske utgravninger. Man kan også søke å finne tilbake til
opprinnelige sagn ved å trekke ut de fragmenter som kan spores tilbake til ytre
påvirkning. Men dette er et møysommelig puslespill, og det kan aldri bli
sikkert. Påvirkning går ofte begge veier, og hvordan kan man bekrefte hvem som
har påvirket hvem? David Hume kom frem til at sannhetsverdien i slike sagn
utelukkende kunne fastsettes i rimeligheten. Dersom sagnet strider mot personlig
erfaring og fornuft, måtte det avskrives. Personlig vil jeg ikke gå så langt.
En avskrivning er 100 % sikker i negativ retning. M.a.o. må jeg ha 100 % bevis
for en slik avskrivning, og i de fleste tilfeller har vi ikke det. Det eneste
jeg kan gå med på er å senke sannsynligheten til et minimum.
I dag eliminerer skriftspråket og elektroniske media mye av disse problemene. Henrik Ibsen kan fortsatt tale direkte til meg, selv om han er død. Hans tanker er udødeliggjort gjennom skriftspråket. Denne muligheten til å langtidslagre informasjon har eksplodert i vårt århundre, gjennom de elektroniske media. Dette fjerner delvis de negative effekter av kreativistens aktiviteter. Vi kan alltid gå tilbake til kilden, og regne informasjonen som like sikker som kilden. På denne måten kan f.eks. Paulus tale til meg kun gjennom ett ledd (oversetteren) enda han levde for snart 2000 år siden.
Kreativisten burde derfor i dag ha mye bedre kår. Vi trenger ikke lengre å være redd for å miste informasjon. Kreativisten kan derfor blande og manipulere med informasjonen så mye som han vil. Dermed får trangen til å skape noe nytt fullt utløp. Men kopimentaliteten sitter fortsatt i mange. Dette hindrer fremgang. Dette kan tradisjonisten selvfølgelig aldri godta. Han er jo, tradisjonen tro, stadig opptatt med å bevare tradisjonen.